tibble(
Verteilung = c(
"Binomial B(n,p)", "Diskrete GV U_d{1..k}",
"Poisson Pois(λ)", "Hypergeom H(N,M,n)",
"Geometrisch Geom(p)",
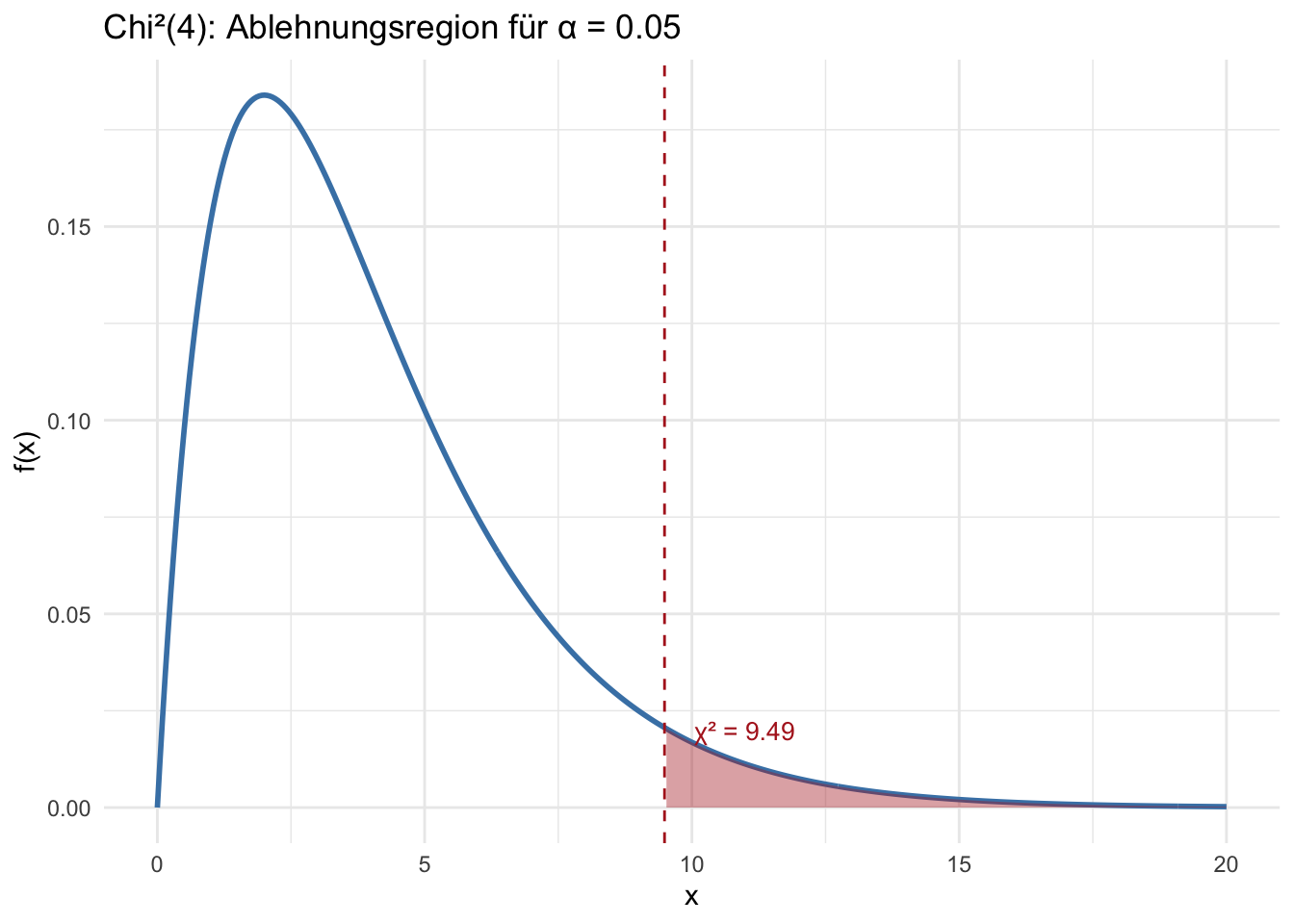
"Normalvert N(μ,σ²)", "Chi² χ²(ν)", "t-Vert t(ν)",
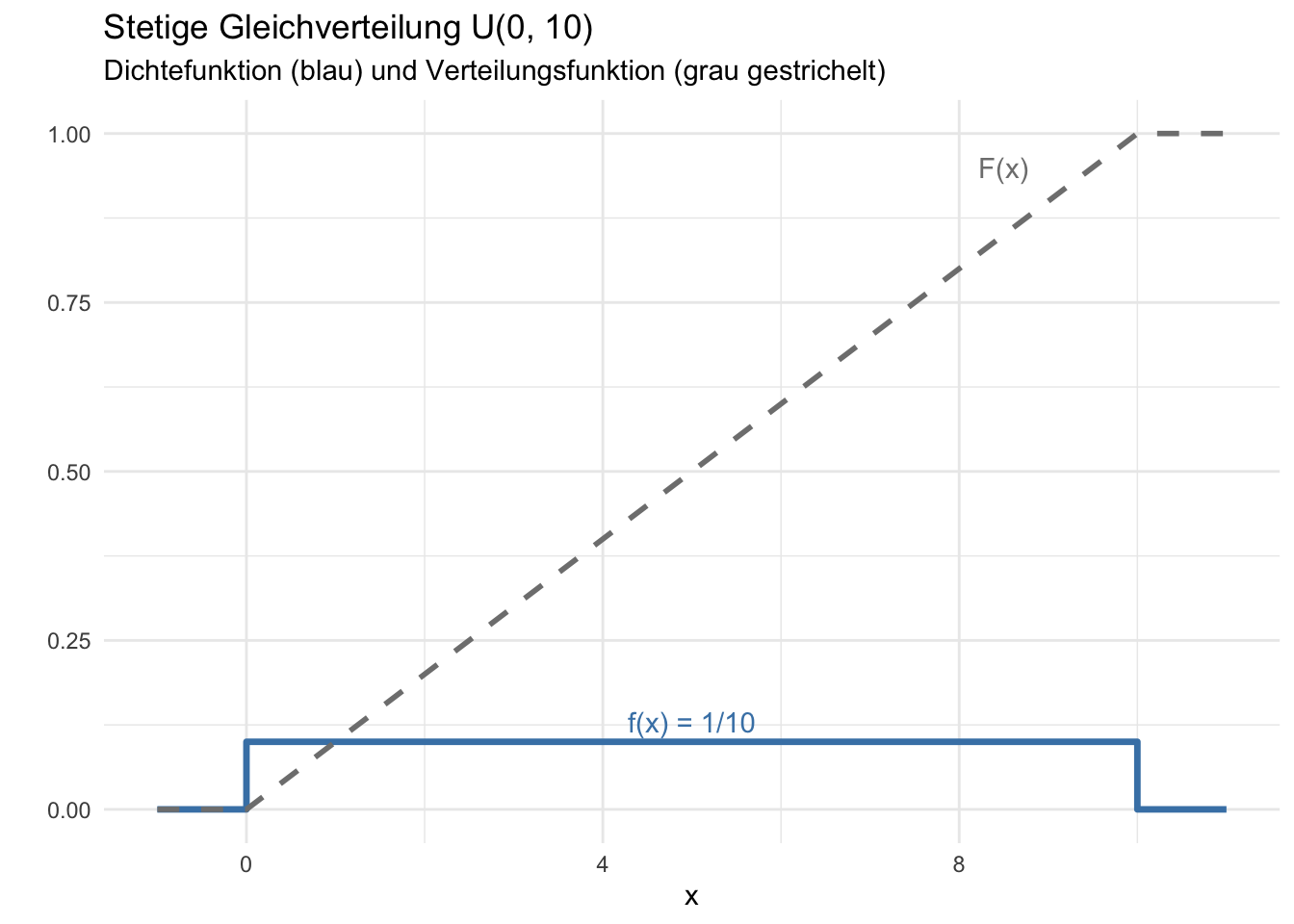
"Stetige GV U(a,b)", "Exponential Exp(λ)"
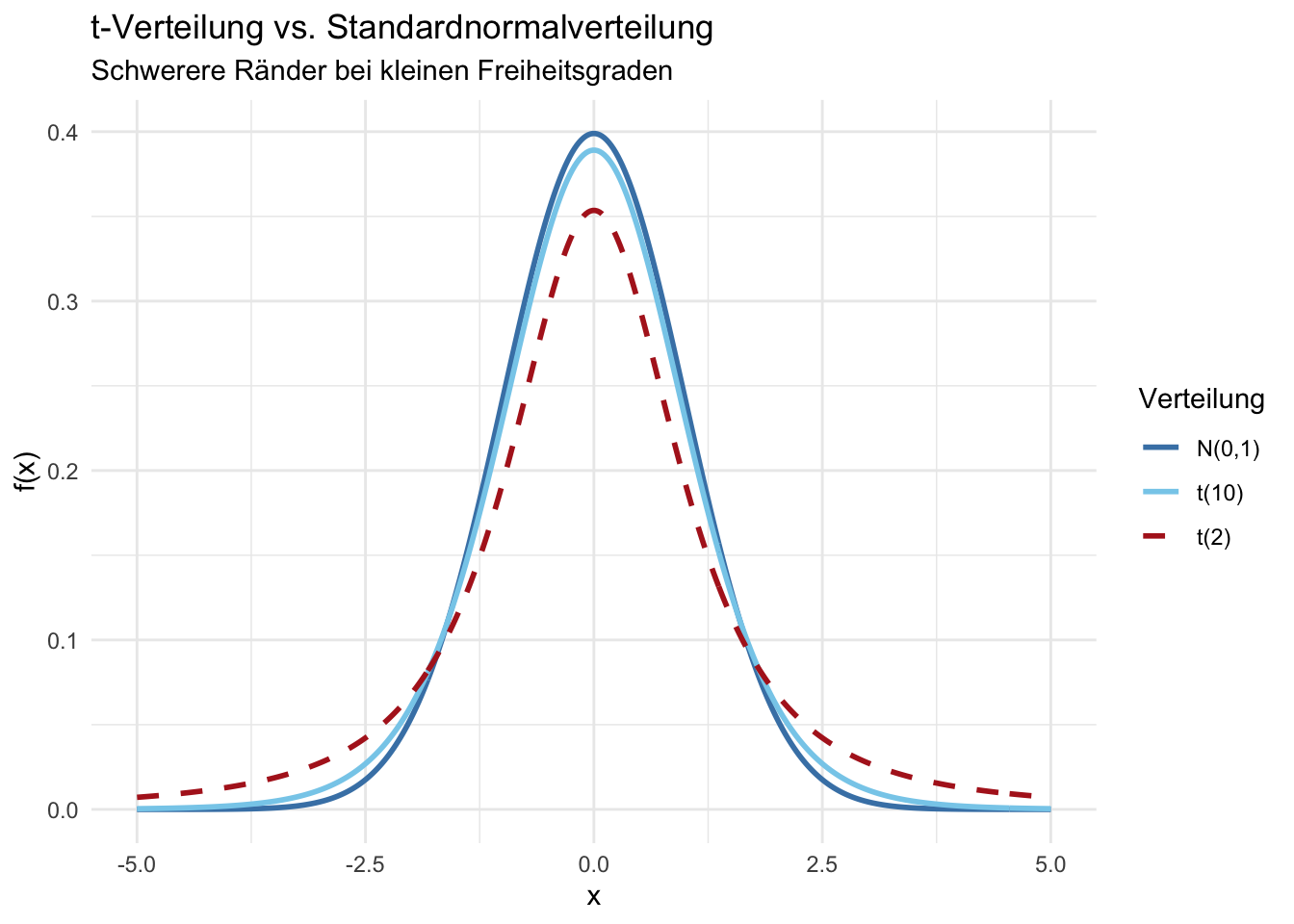
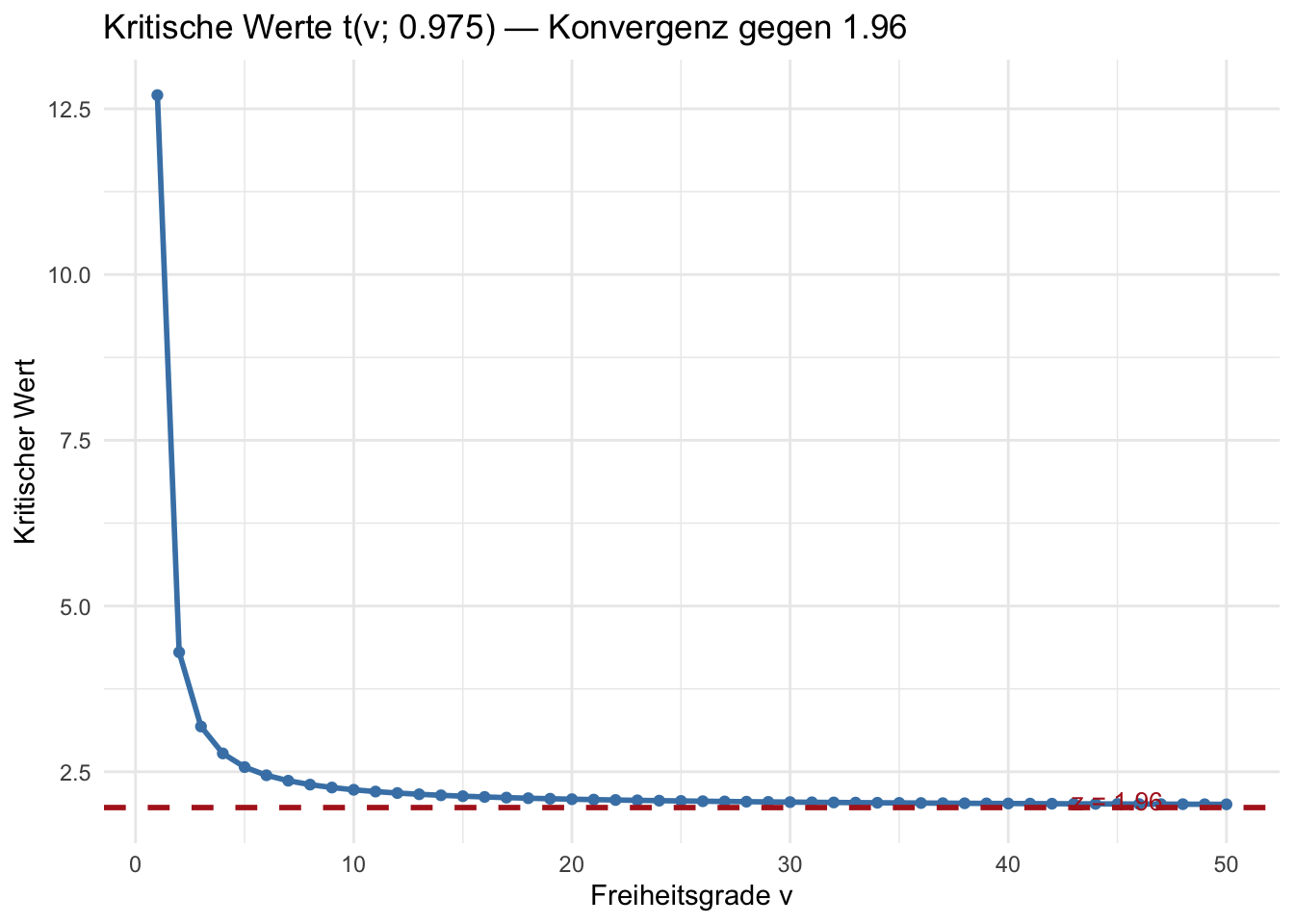
),
Typ = c(rep("Diskret", 5), rep("Stetig", 5)),
`E[X]` = c("np", "(k+1)/2", "λ", "nM/N", "(1-p)/p",
"μ", "ν", "0", "(a+b)/2", "1/λ"),
`Var(X)` = c("np(1-p)", "(k²-1)/12", "λ", "np/N·(N-M)/N·(N-n)/(N-1)", "(1-p)/p²",
"σ²", "2ν", "ν/(ν-2)", "(b-a)²/12", "1/λ²"),
`R-Prefix` = c("binom","—","pois","hyper","geom","norm","chisq","t","unif","exp")
) |>
knitr::kable(caption = "Übersicht aller behandelten Verteilungen") |>
kableExtra::kable_styling(bootstrap_options = c("striped", "hover"), full_width = TRUE) |>
kableExtra::row_spec(0, bold = TRUE) |>
kableExtra::pack_rows("Diskrete Verteilungen", 1, 5) |>
kableExtra::pack_rows("Stetige Verteilungen", 6, 10)